Topic 3, Mix Questions
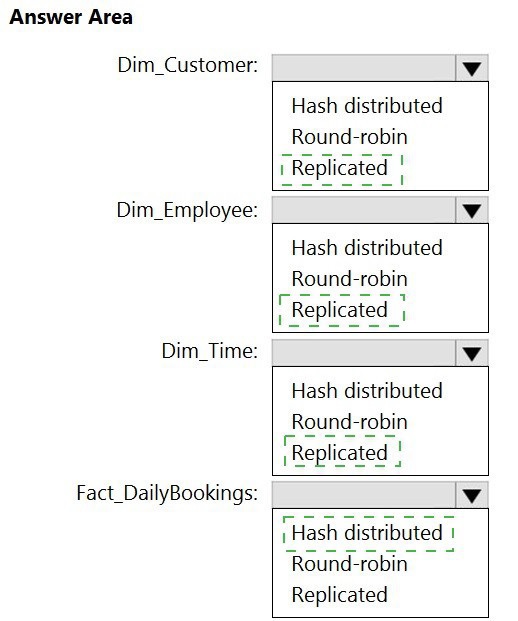
You have a data model that you plan to implement in a data warehouse in Azure Synapse
Analytics as shown in the following exhibit.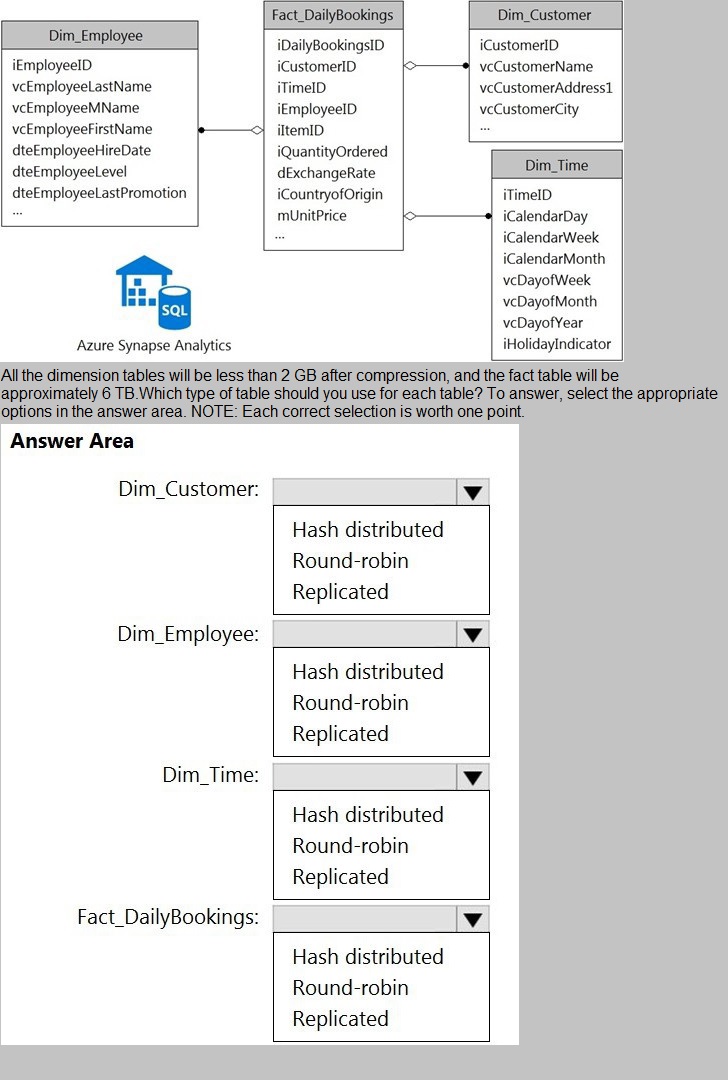
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that
each tweet is counted only once.
Solution: You use a hopping window that uses a hop size of 5 seconds and a window size
10 seconds.
Does this meet the goal?
A.
Yes
B.
No
No
Instead use a tumbling window. Tumbling windows are a series of fixed-sized, nonoverlapping
and contiguous time intervals.
Reference:
https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-streamanalytics
You are designing a sales transactions table in an Azure Synapse Analytics dedicated SQL
pool. The table will contains approximately 60 million rows per month and will be partitioned
by month. The table will use a clustered column store index and round-robin distribution.
Approximately how many rows will there be for each combination of distribution and
partition?
A.
1 million
B.
5 million
C.
20 million
D.
60 million
60 million
Explanation: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-datawarehouse/
sql-data-warehouse-tables-partition
You have an Azure data factory.
You need to examine the pipeline failures from the last 60 days.
What should you use?
A.
the Activity log blade for the Data Factory resource
B.
the Monitor & Manage app in Data Factory
C.
the Resource health blade for the Data Factory resource
D.
Azure Monitor
Azure Monitor
Explanation:
Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to
keep that data for a longer time.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
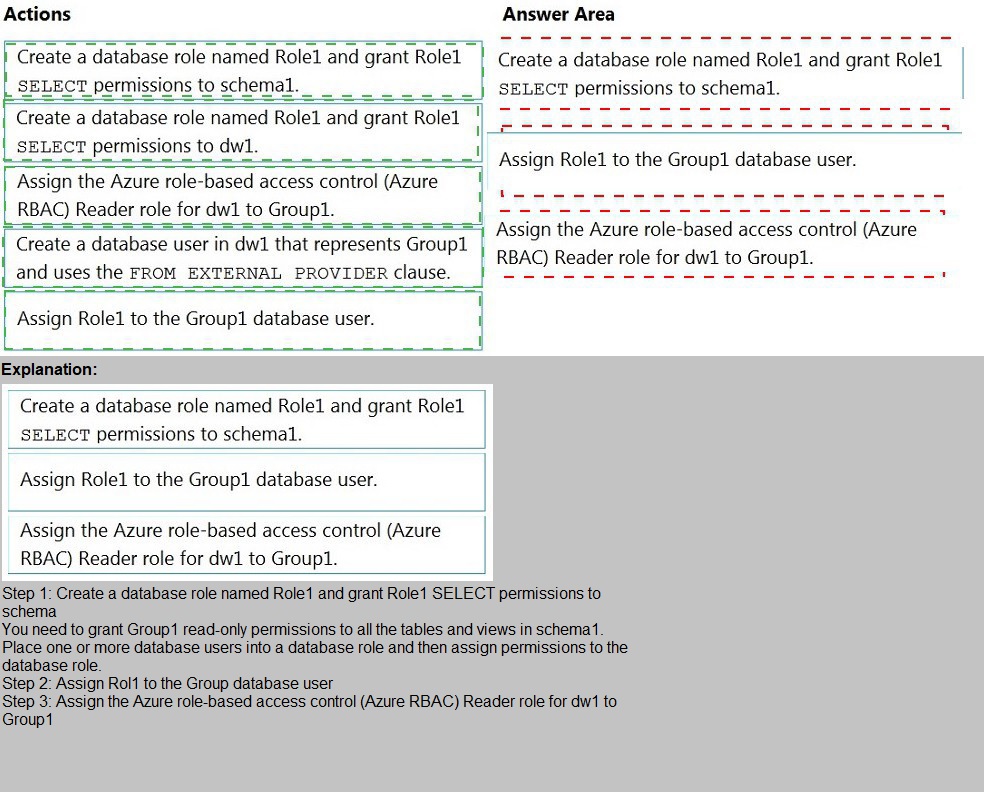
You have an Azure Active Directory (Azure AD) tenant that contains a security group
named Group1. You have an Azure Synapse Analytics dedicated SQL pool named dw1
that contains a schema named schema1.
You need to grant Group1 read-only permissions to all the tables and views in schema1.
The solution must use the principle of least privilege.
Which three actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of
the correct orders you select.
You implement an enterprise data warehouse in Azure Synapse Analytics
You have a large fact table that is 10 terabytes (TB) in size.
Incoming queries use the primary key SaleKey column to retrieve data as displayed in the
following table: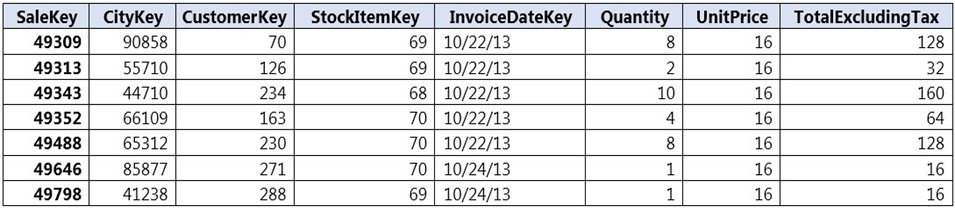
You need to distribute the large fact table across multiple nodes to optimize performance of
the table.
Which technology should you use?
A.
hash distributed table with clustered index
B.
hash distributed table with clustered Columnstore index
C.
round robin distributed table with clustered index
D.
round robin distributed table with clustered Columnstore index
E.
heap table with distribution replicate
hash distributed table with clustered Columnstore index
Explanation:
Hash-distributed tables improve query performance on large fact tables.
Columnstore indexes can achieve up to 100x better performance on analytics and data
warehousing workloads
and up to 10x better data compression than traditional rowstore indexes.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tablesdistribute
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexesquery-
performance
You need to schedule an Azure Data Factory pipeline to execute when a new file arrives in
an Azure Data Lake Storage Gen2 container.
Which type of trigger should you use?
A.
on-demand
B.
tumbling window
C.
schedule
D.
event
event
Explanation:
Event-driven architecture (EDA) is a common data integration pattern that involves
production, detection, consumption, and reaction to events. Data integration scenarios
often require Data Factory customers to trigger
pipelines based on events happening in storage account, such as the arrival or deletion of
a file in Azure Blob Storage account.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-event-trigger
You plan to ingest streaming social media data by using Azure Stream Analytics. The data
will be stored in files in Azure Data Lake Storage, and then consumed by using Azure
Datiabricks and PolyBase in Azure Synapse Analytics.
You need to recommend a Stream Analytics data output format to ensure that the queries
from Databricks and PolyBase against the files encounter the fewest possible errors. The
solution must ensure that the tiles can be queried quickly and that the data type information
is retained.
What should you recommend?
A.
Parquet
B.
Avro
C.
CSV
D.
JSON
Avro
Explanation: The Avro format is great for data and message preservation.Avro schema
with its support for evolution is essential for making the data robust for streaming
architectures like Kafka, and with the metadata that schema provides, you can reason on
the data. Having a schema provides robustness in providing meta-data about the data
stored in Avro records which are self- documenting the
data.References:http://cloudurable.com/blog/avro/index.html
You create an Azure Databricks cluster and specify an additional library to install.
When you attempt to load the library to a notebook, the library in not found.
You need to identify the cause of the issue.
What should you review?
A.
notebook logs
B.
cluster event logs
C.
global init scripts logs
D.
workspace logs
global init scripts logs
Explanation:
Cluster-scoped Init Scripts: Init scripts are shell scripts that run during the startup of each
cluster node before the Spark driver or worker JVM starts. Databricks customers use init
scripts for various purposes such as installing custom libraries, launching background
processes, or applying enterprise security policies.
Logs for Cluster-scoped init scripts are now more consistent with Cluster Log Delivery and
can be found in the same root folder as driver and executor logs for the cluster
You have an Azure Synapse Analytics dedicated SQL Pool1. Pool1 contains a partitioned
fact table named dbo.Sales and a staging table named stg.Sales that has the matching
table and partition definitions.
You need to overwrite the content of the first partition in dbo.Sales with the content of the
same partition in stg.Sales. The solution must minimize load times.
What should you do?
A.
Switch the first partition from dbo.Sales to stg.Sales.
B.
Switch the first partition from stg.Sales to dbo. Sales.
C.
Update dbo.Sales from stg.Sales.
D.
Insert the data from stg.Sales into dbo.Sales.
Insert the data from stg.Sales into dbo.Sales.
| Page 6 out of 21 Pages |
| Previous |
Copyright © - All Rights Reserved