Topic 3, Mix Questions
You use Azure Data Lake Storage Gen2.
You need to ensure that workloads can use filter predicates and column projections to filter
data at the time the data is read from disk.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A.
Reregister the Microsoft Data Lake Store resource provider.
B.
Reregister the Azure Storage resource provider.
C.
Create a storage policy that is scoped to a container.
D.
Register the query acceleration feature.
E.
Create a storage policy that is scoped to a container prefix filter.
Reregister the Azure Storage resource provider.
Register the query acceleration feature.
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure. The
workspace will contain the following three workloads:
A workload for data engineers who will use Python and SQL.
A workload for jobs that will run notebooks that use Python, Scala, and SOL.
A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for
Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data
scientists and data engineers provide packaged notebooks for deployment to the
cluster.
All the data scientists must be assigned their own cluster that terminates
automatically after 120 minutes of inactivity. Currently, there are three data
scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster
for the data engineers, and a High Concurrency cluster for the jobs.
Does this meet the goal?
A.
Yes
B.
No
Yes
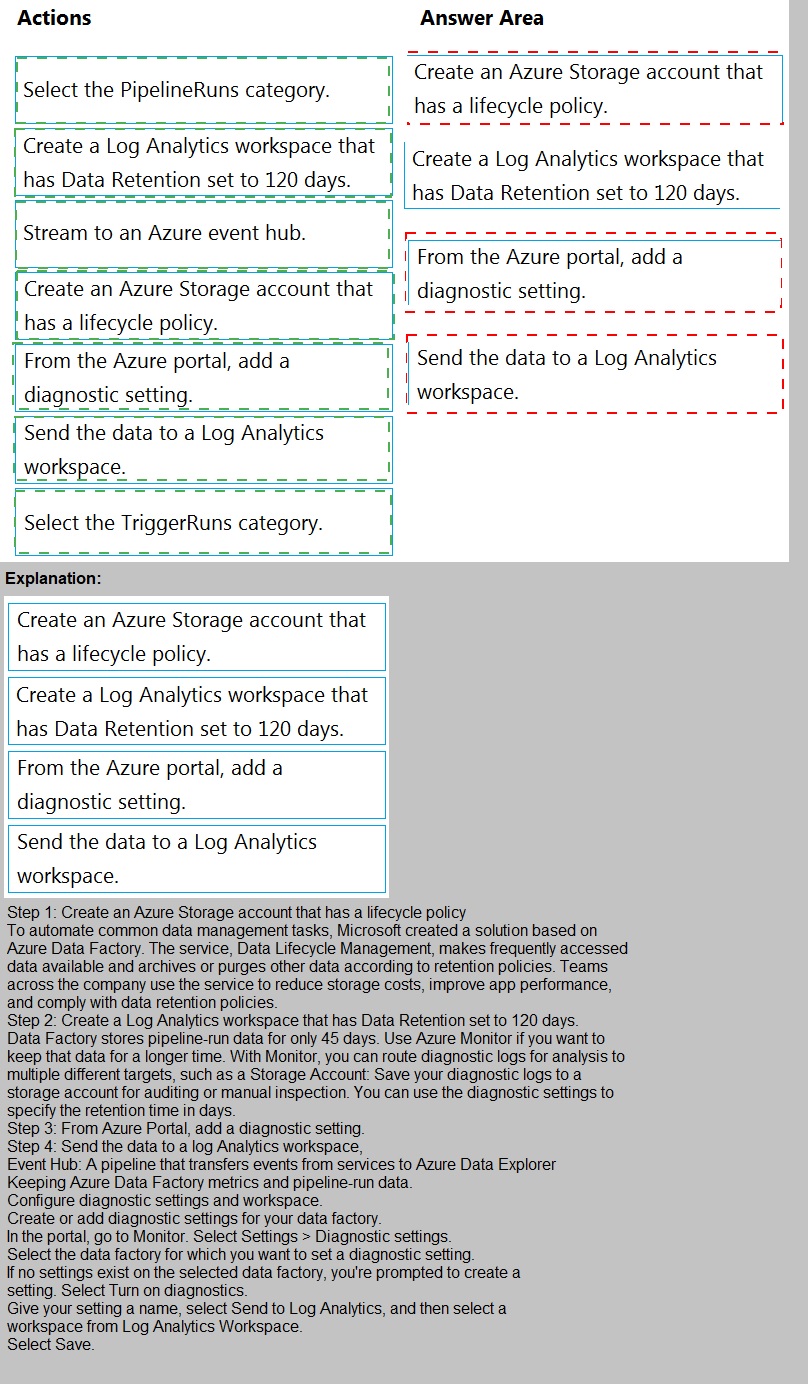
You have an Azure data factory.
You need to ensure that pipeline-run data is retained for 120 days. The solution must
ensure that you can query the data by using the Kusto query language.
Which four actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of
the correct orders you select.
You have an Azure Data Lake Storage Gen2 container that contains 100 TB of data.
You need to ensure that the data in the container is available for read workloads in a
secondary region if an outage occurs in the primary region. The solution must minimize
costs.
Which type of data redundancy should you use?
A.
zone-redundant storage (ZRS)
B.
read-access geo-redundant storage (RA-GRS)
C.
locally-redundant storage (LRS)
D.
geo-redundant storage (GRS)
locally-redundant storage (LRS)
Note: This question is part of a series of questions that present the same scenario. Each
question in the series contains a unique solution that might meet the stated goals. Some
question sets might have more than one correct solution, while others might not have a
correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text
and numerical values. 75% of the rows contain description data that has an average length
of 1.1 MB.
You plan to copy the data from the storage account to an enterprise data warehouse in
Azure Synapse Analytics.
You need to prepare the files to ensure that the data copies quickly.
Solution: You convert the files to compressed delimited text files.
Does this meet the goal?
A.
Yes
B.
No
Yes
All file formats have different performance characteristics. For the fastest load, use
compressed delimited text files.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
You are developing a solution that will stream to Azure Stream Analytics. The solution will
have both streaming data and reference data.
Which input type should you use for the reference data?
A.
Azure Cosmos DB
B.
Azure Blob storage
C.
Azure IoT Hub
D.
Azure Event Hubs
Azure Blob storage
Explanation:
Stream Analytics supports Azure Blob storage and Azure SQL Database as the storage
layer for Reference Data.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-use-referencedata
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following Transact-SQL statement.
You need to alter the table to meet the following requirements:
Ensure that users can identify the current manager of employees.
Support creating an employee reporting hierarchy for your entire company.
Provide fast lookup of the managers’ attributes such as name and job title.
Which column should you add to the table?
A.
[ManagerEmployeeID] [int] NULL
B.
[ManagerEmployeeID] [smallint] NULL
C.
[ManagerEmployeeKey] [int] NULL
D.
[ManagerName] [varchar](200) NULL
[ManagerEmployeeID] [int] NULL
Explanation:
Use the same definition as the EmployeeID column.
Reference:
https://docs.microsoft.com/en-us/analysis-services/tabular-models/hierarchies-ssas-tabular
You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.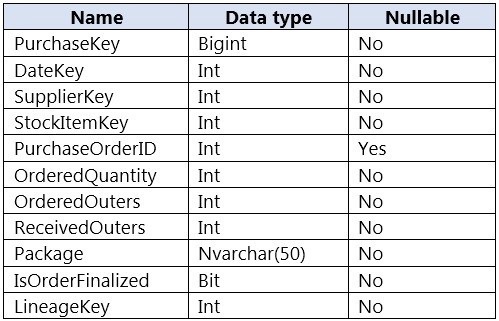
FactPurchase will have 1 million rows of data added daily and will contain three years of
data.
Transact-SQL queries similar to the following query will be executed daily.
SELECT
SupplierKey, StockItemKey, COUNT(*)
FROM FactPurchase
WHERE DateKey >= 20210101
AND DateKey <= 20210131
GROUP By SupplierKey, StockItemKey
Which table distribution will minimize query times?
A.
round-robin
B.
replicated
C.
hash-distributed on DateKey
D.
hash-distributed on PurchaseKey
hash-distributed on PurchaseKey
Hash-distributed tables improve query performance on large fact tables, and are the focus
of this article. Round-robin tables are useful for improving loading speed.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-datawarehouse-
tables-distribute
You have an Azure Synapse Analystics dedicated SQL pool that contains a table named
Contacts. Contacts contains a column named Phone.
You need to ensure that users in a specific role only see the last four digits of a phone
number when querying the Phone column.
What should you include in the solution?
A.
A. a default value
B.
dynamic data masking
C.
row-level security (RLS)
D.
column encryption
E.
table partitions
row-level security (RLS)
You are designing an inventory updates table in an Azure Synapse Analytics dedicated
SQL pool. The table will have a clustered columnstore index and will include the following
columns:
• EventDate: 1 million per day
• EventTypelD: 10 million per event type
• WarehouselD: 100 million per warehouse
ProductCategoryTypeiD: 25 million per product category type
You identify the following usage patterns:
Analyst will most commonly analyze transactions for a warehouse.
Queries will summarize by product category type, date, and/or inventory event type.
You need to recommend a partition strategy for the table to minimize query times.
On which column should you recommend partitioning the table?
A.
ProductCategoryTypeID
B.
EventDate
C.
WarehouseID
D.
EventTypeID
EventTypeID
| Page 5 out of 21 Pages |
| Previous |
Copyright © - All Rights Reserved