Topic 3, Mix Questions
You need to design an Azure Synapse Analytics dedicated SQL pool that meets the following requirements:
Can return an employee record from a given point in time.
Maintains the latest employee information.
Minimizes query complexity.
How should you model the employee data?
A.
as a temporal table
B.
as a SQL graph table
C.
as a degenerate dimension table
D.
as a Type 2 slowly changing dimension (SCD) table
as a Type 2 slowly changing dimension (SCD) table
Explanation:
A Type 2 SCD supports versioning of dimension members. Often the source system
doesn't store versions, so the data warehouse load process detects and manages changes
in a dimension table. In this case, the dimension table must use a surrogate key to provide
a unique reference to a version of the dimension member. It also includes columns that
define the date range validity of the version (for example, StartDate and EndDate) and
possibly a flag column (for example, IsCurrent) to easily filter by current dimension
members.
Reference:
https://docs.microsoft.com/en-us/learn/modules/populate-slowly-changing-dimensionsazure-
synapse-analytics-pipelines/3-choose-between-dimension-types
You have an Azure Synapse Analytics serverless SQL pool named Pool1 and an Azure
Data Lake Storage Gen2 account named storage1. The AllowedBlobpublicAccess porperty
is disabled for storage1.
You need to create an external data source that can be used by Azure Active Directory
(Azure AD) users to access storage1 from Pool1.
What should you create first?
A.
an external resource pool
B.
a remote service binding
C.
database scoped credentials
D.
an external library
database scoped credentials
Note: This question is part of a series of questions that present the same scenario.
Each question in the series contains a unique solution that might meet the stated
goals. Some question sets might have more than one correct solution, while others
might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You plan to create an Azure Databricks workspace that has a tiered structure. The
workspace will contain the following three workloads:
A workload for data engineers who will use Python and SQL.
A workload for jobs that will run notebooks that use Python, Scala, and SOL.
A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for
Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data
scientists and data engineers provide packaged notebooks for deployment to the
cluster.
All the data scientists must be assigned their own cluster that terminates
automatically after 120 minutes of inactivity. Currently, there are three data
scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a High Concurrency cluster for each data scientist, a High
Concurrency cluster for the data engineers, and a Standard cluster for the jobs.
Does this meet the goal?
A.
Yes
B.
No
No
Explanation:
Need a High Concurrency cluster for the jobs.
Standard clusters are recommended for a single user. Standard can run workloads
developed in any language:
Python, R, Scala, and SQL.
A high concurrency cluster is a managed cloud resource. The key benefits of high
concurrency clusters are that
they provide Apache Spark-native fine-grained sharing for maximum resource utilization
and minimum query
latencies.
Reference:
https://docs.azuredatabricks.net/clusters/configure.html
You plan to implement an Azure Data Lake Storage Gen2 container that will contain CSV
files. The size of the files will vary based on the number of events that occur per hour.
File sizes range from 4.KB to 5 GB.
You need to ensure that the files stored in the container are optimized for batch processing.
What should you do?
A.
Compress the files.
B.
Merge the files.
C.
Convert the files to JSON
D.
Convert the files to Avro.
Convert the files to Avro.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some
question sets might have more than one correct solution, while others might not have a
correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a
result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text
and numerical values. 75% of the rows contain description data that has an average length
of 1.1 MB.
You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is more than 1 MB.
Does this meet the goal?
A.
Yes
B.
No
No
Explanation:
Instead modify the files to ensure that each row is less than 1 MB.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
You plan to implement an Azure Data Lake Gen2 storage account.
You need to ensure that the data lake will remain available if a data center fails in the primary Azure region.
The solution must minimize costs.
Which type of replication should you use for the storage account?
A.
geo-redundant storage (GRS)
B.
zone-redundant storage (ZRS)
C.
locally-redundant storage (LRS)
D.
geo-zone-redundant storage (GZRS)
geo-redundant storage (GRS)
Explanation:
Geo-redundant storage (GRS) copies your data synchronously three times within a single
physical location in the primary region using LRS. It then copies your data asynchronously
to a single physical location in the secondary region.
Reference:
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy
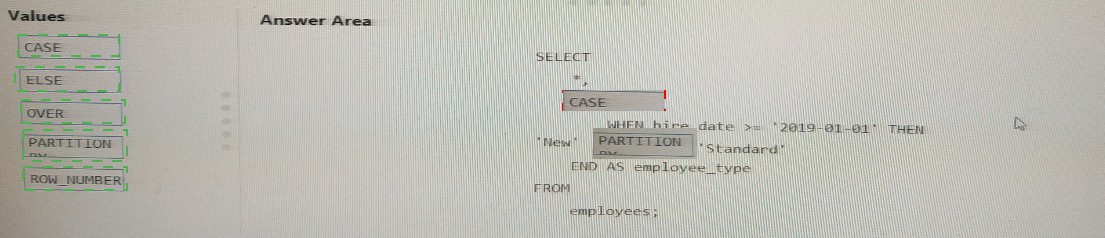
You have the following table named Employees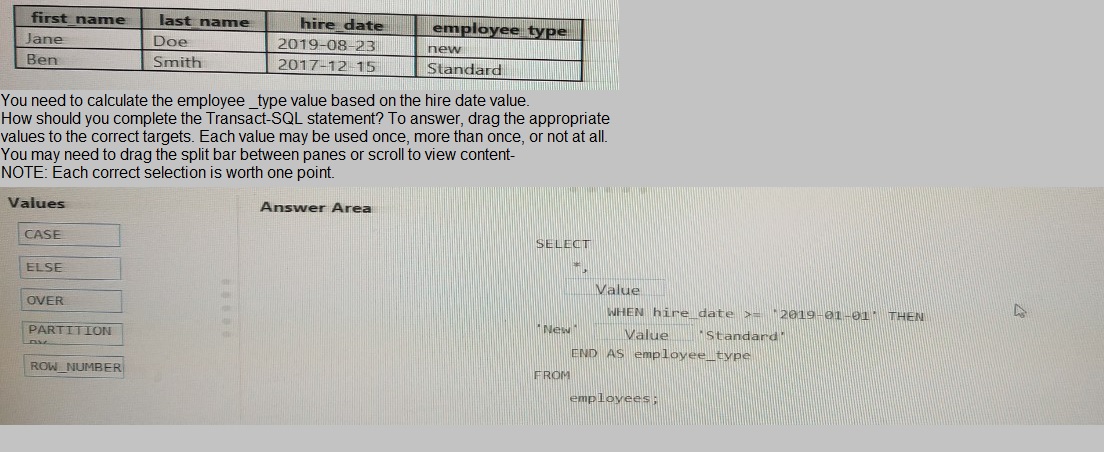
You have an enterprise-wide Azure Data Lake Storage Gen2 account. The data lake is
accessible only through an Azure virtual network named VNET1.
You are building a SQL pool in Azure Synapse that will use data from the data lake.
Your company has a sales team. All the members of the sales team are in an Azure Active
Directory group named Sales. POSIX controls are used to assign the Sales group access
to the files in the data lake.
You plan to load data to the SQL pool every hour.
You need to ensure that the SQL pool can load the sales data from the data lake.
Which three actions should you perform? Each correct answer presents part of the
solution.
NOTE: Each area selection is worth one point.
A.
Add the managed identity to the Sales group.
B.
Use the managed identity as the credentials for the data load process.
C.
Create a shared access signature (SAS).
D.
Add your Azure Active Directory (Azure AD) account to the Sales group.
E.
Use the snared access signature (SAS) as the credentials for the data load process.
F.
Create a managed identity.
Add the managed identity to the Sales group.
Add your Azure Active Directory (Azure AD) account to the Sales group.
Create a managed identity.
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1. You need to verify whether the size of the transaction log file for each distribution of DW1 is smaller than 160 GB.
What should you do?
A.
On the master database, execute a query against the
sys.dm_pdw_nodes_os_performance_counters dynamic management view.
B.
From Azure Monitor in the Azure portal, execute a query against the logs of DW1.
C.
On DW1, execute a query against the sys.database_files dynamic management view.
D.
Execute a query against the logs of DW1 by using the
Get-AzOperationalInsightSearchResult PowerShell cmdlet
On the master database, execute a query against the
sys.dm_pdw_nodes_os_performance_counters dynamic management view.
Explanation:
The following query returns the transaction log size on each distribution. If one of the log
files is reaching 160 GB, you should consider scaling up your instance or limiting your
transaction size.
- Transaction log size
SELECT
instance_name as distribution_db,
cntr_value*1.0/1048576 as log_file_size_used_GB,
pdw_node_id
FROM sys.dm_pdw_nodes_os_performance_counters
WHERE
instance_name like 'Distribution_%'
AND counter_name = 'Log File(s) Used Size (KB)'
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-managemonitor
A company purchases IoT devices to monitor manufacturing machinery. The company uses an IoT appliance to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
A.
Azure Stream Analytics cloud job using Azure PowerShell
B.
Azure Analysis Services using Azure Portal
C.
Azure Data Factory instance using Azure Portal
D.
Azure Analysis Services using Azure PowerShell
Azure Stream Analytics cloud job using Azure PowerShell
Explanation:
Stream Analytics is a cost-effective event processing engine that helps uncover real-time
insights from devices, sensors, infrastructure, applications and data quickly and easily.
Monitor and manage Stream Analytics resources with Azure PowerShell cmdlets and
powershell scripting that execute basic Stream Analytics tasks.
Reference:
https://cloudblogs.microsoft.com/sqlserver/2014/10/29/microsoft-adds-iot-streaminganalytics-
data-production-and-workflow-services-to-azure/
| Page 4 out of 21 Pages |
| Previous |
Copyright © - All Rights Reserved