Topic 5: Describe features of conversational AI workloads on Azure
Which parameter should you configure to produce more verbose responses from a chat solution that uses the Azure OpenAI GPT-3.5 model?
A. Presence penalty
B. Temperature
C. Stop sequence
D. Max response
Match the principles of responsible AI to the appropriate descriptions.
To answer, drag the appropriate principle from the column on the left to its description on
the right. Each principle may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.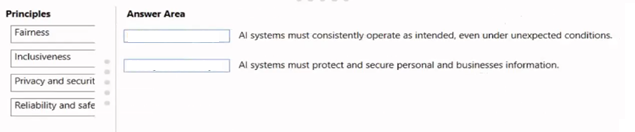

To complete the sentence, select the appropriate option in the answer area.
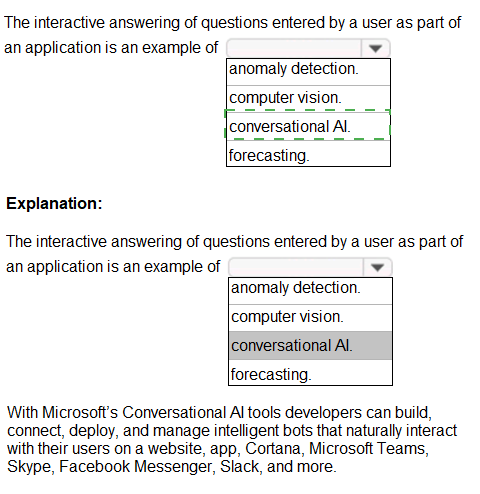
Select the answer that correctly completes the sentence.

You have the following dataset.

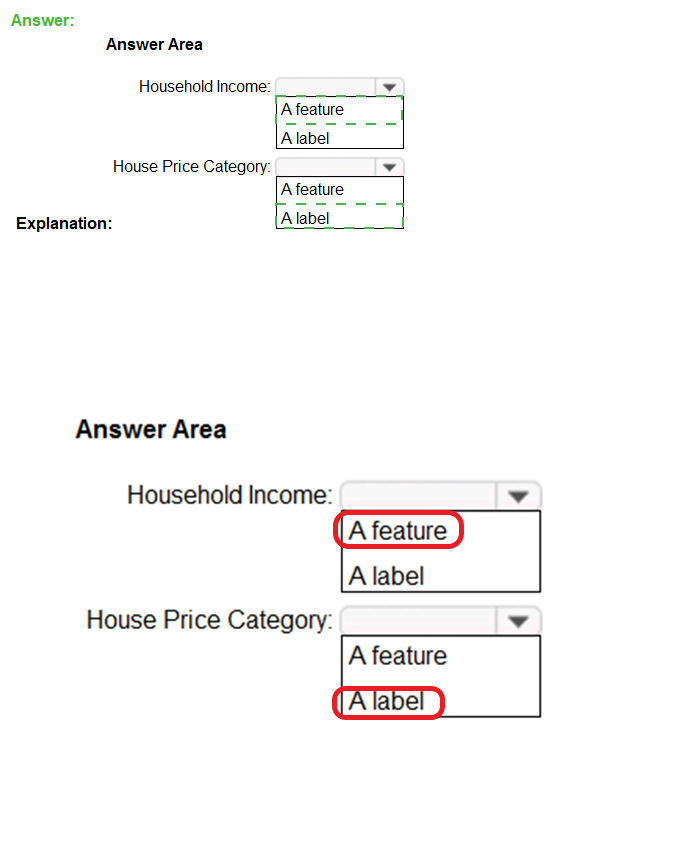
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

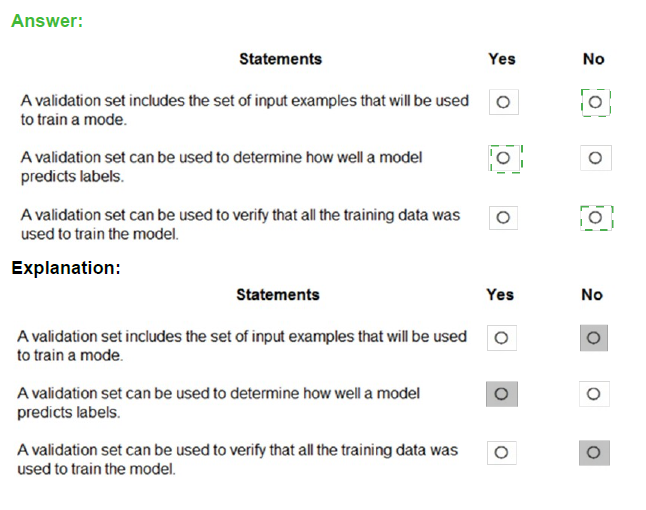
Box 1: No
The validation dataset is different from the test dataset that is held back from the training of
the model.
Box 2: Yes
A validation dataset is a sample of data that is used to give an estimate of model skill while tuning model’s hyperparameters.
Box 3: No
The Test Dataset, not the validation set, used for this. The Test Dataset is a sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
For each of the following statements, select Yes if the statement is true. Otherwise, select
No.
NOTE: Each correct selection is worth one point.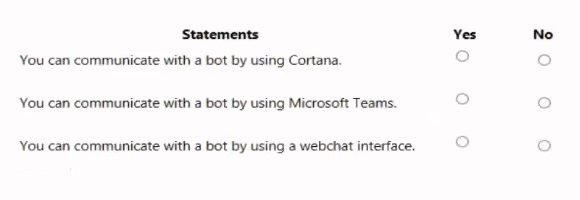
You are developing a conversational AI solution that will communicate with users through
multiple channels including email, Microsoft Teams, and webchat.
Which service should you use?
A. Text Analytics
B. Azure Bot Service
C. Translator
D. Form Recognizer
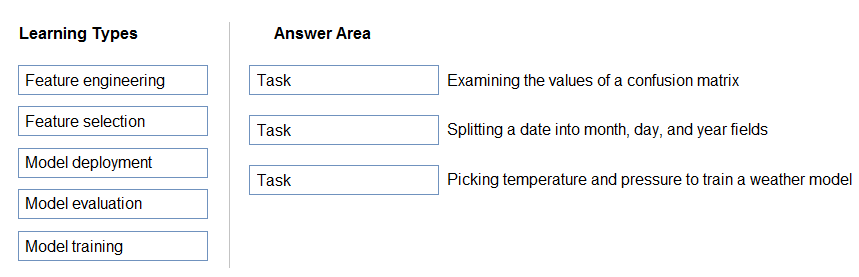
Match the machine learning tasks to the appropriate scenarios.
To answer, drag the appropriate task from the column on the left to its scenario on the right. Each task may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
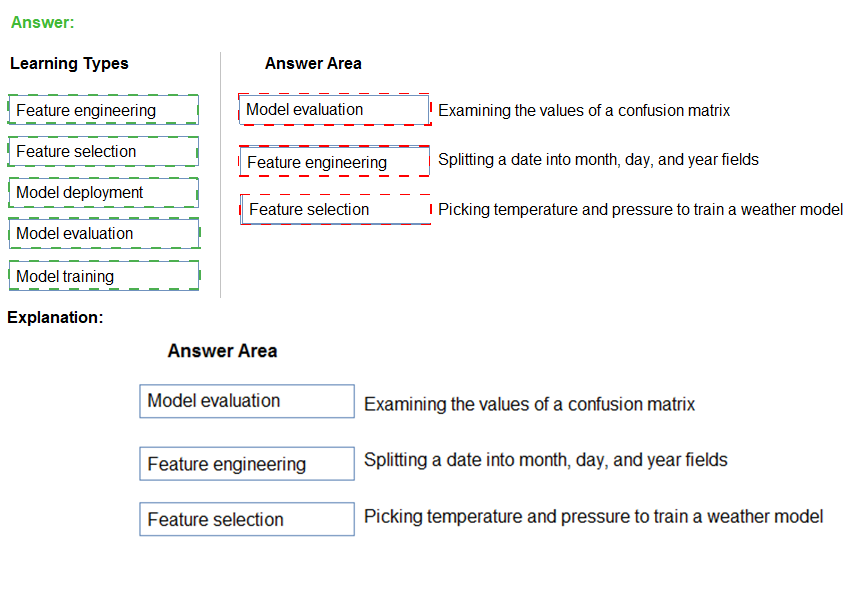
Box 1: Model evaluation
The Model evaluation module outputs a confusion matrix showing the number of true positives, false negatives, false positives, and true negatives, as well as ROC, Precision/Recall, and Lift curves.
Box 2: Feature engineering
Feature engineering is the process of using domain knowledge of the data to create features that help ML algorithms learn better. In Azure Machine Learning, scaling and normalization techniques are applied to facilitate feature engineering. Collectively, these techniques and feature engineering are referred to as featurization.
Note: Often, features are created from raw data through a process of feature engineering. For example, a time stamp in itself might not be useful for modeling until the information is transformed into units of days, months, or categories that are relevant to the problem, such as holiday versus working day.
Box 3: Feature selection
In machine learning and statistics, feature selection is the process of selecting a subset of relevant, useful features to use in building an analytical model. Feature selection helps narrow the field of data to the most valuable inputs. Narrowing the field of data helps reduce noise and improve training performance.
You need to predict the sea level in meters for the next 10 years. Which type of machine learning should you use?
A. classification
B. regression
C. clustering
| Page 9 out of 27 Pages |
| Previous |
Copyright © - All Rights Reserved