Topic 1: Wide World Importers
Case study
This is a case study. Case studies are not timed separately. You can use as much exam
time as you would like to complete each case. However, there may be additional case
studies and sections on this exam. You must manage your time to ensure that you are able
to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information
that is provided in the case study. Case studies might contain exhibits and other resources
that provide more information about the scenario that is described in the case study. Each
question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review
your answers and to make changes before you move to the next section of the exam. After
you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the
left pane to explore the content of the case study before you answer the questions. Clicking
these buttons displays information such as business requirements, existing environment,
and problem statements. If the case study has an All Information tab, note that the
information displayed is identical to the information displayed on the subsequent tabs.
When you are ready to answer a question, click the Question button to return to the
question.
Overview
Existing Environment
A company named Wide World Importers is developing an e-commerce platform.
You are working with a solutions architect to design and implement the features of the ecommerce platform. The platform will use microservices and a serverless environment built
on Azure.
Wide World Importers has a customer base that includes English, Spanish, and
Portuguese speakers.
Applications
Wide World Importers has an App Service plan that contains the web apps shown in the
following table.

You are planning the product creation project.
You need to build the REST endpoint to create the multilingual product descriptions.
How should you complete the URI? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
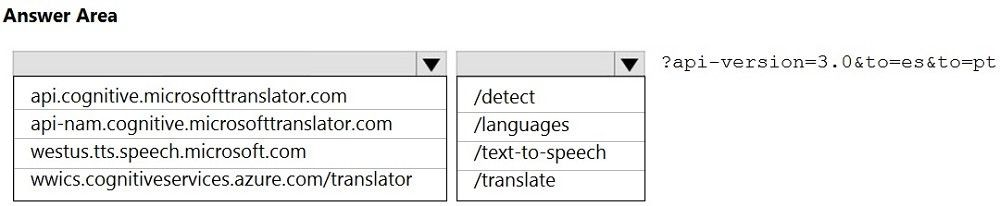

Explanation:
Box 1: api-nam.cognitive.microsofttranslator.com
https://docs.microsoft.com/en-us/azure/cognitive-services/translator/reference/v3-0-
reference
Box 2: /translate
You are developing the shopping on-the-go project.
You need to build the Adaptive Card for the chatbot.
How should you complete the code? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.


You need to develop code to upload images for the product creation project. The solution
must meet the accessibility requirements.
How should you complete the code? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
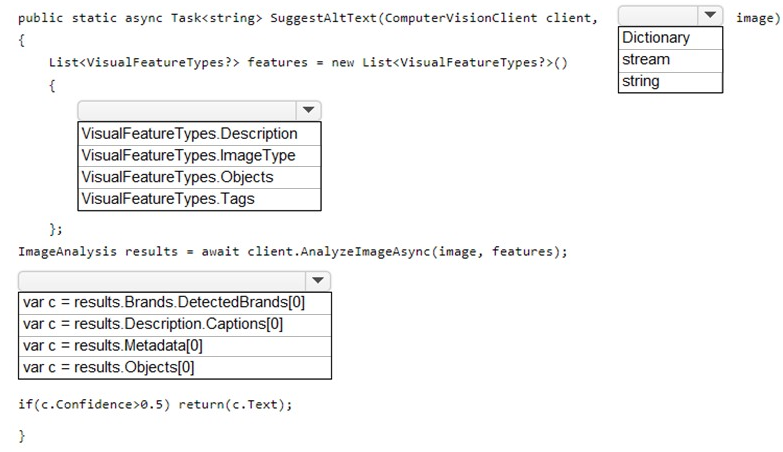
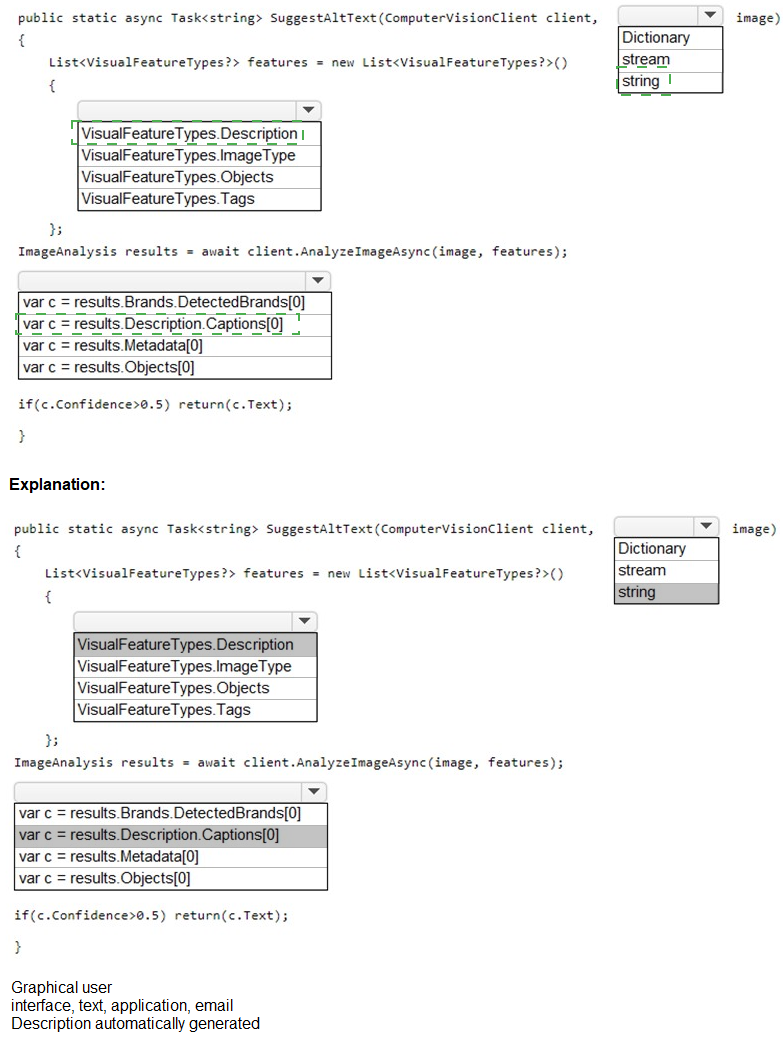
You are developing the shopping on-the-go project.
You are configuring access to the QnA Maker resources.
Which role should you assign to AllUsers and LeadershipTeam? To answer, select the
appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

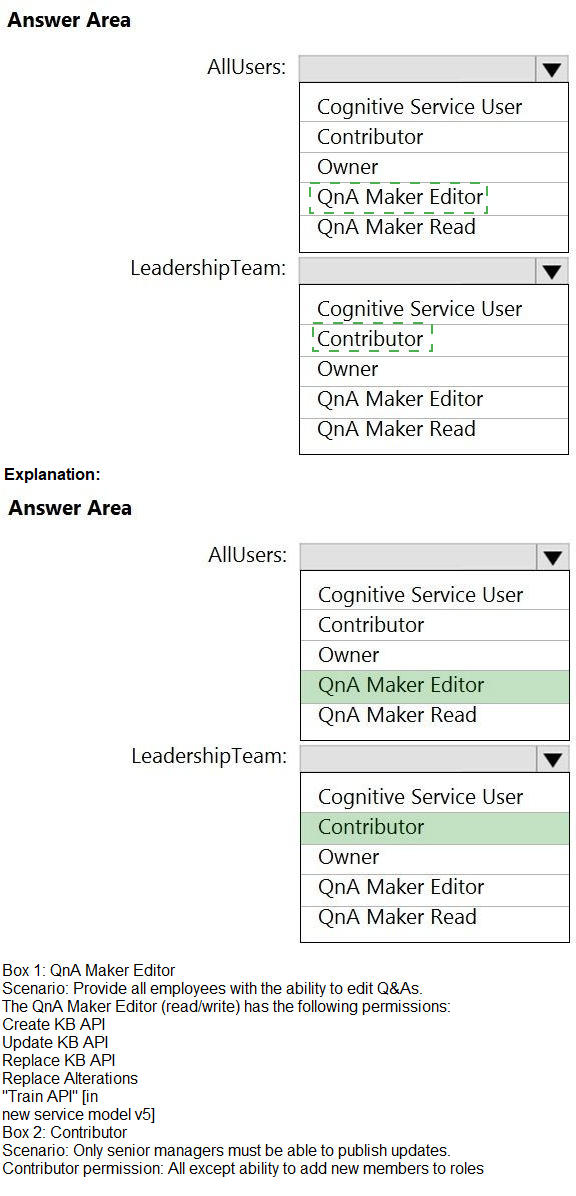
You are developing the smart e-commerce project.
You need to implement autocompletion as part of the Cognitive Search solution.
Which three actions should you perform? Each correct answer presents part of the
solution. (Choose three.)
NOTE: Each correct selection is worth one point.
A.
Make API queries to the autocomplete endpoint and include suggesterName in the body.
B.
Add a suggester that has the three product name fields as source fields.
C.
Make API queries to the search endpoint and include the product name fields in the
searchFields query parameter.
D.
Add a suggester for each of the three product name fields
E.
Set the searchAnalyzer property for the three product name variants.
F.
Set the analyzer property for the three product name variants.
Make API queries to the autocomplete endpoint and include suggesterName in the body.
Add a suggester that has the three product name fields as source fields.
Set the analyzer property for the three product name variants.
Scenario: Support autocompletion and autosuggestion based on all product name variants.
A: Call a suggester-enabled query, in the form of a Suggestion request or Autocomplete
request, using an API. API usage is illustrated in the following call to the Autocomplete
REST API.
POST /indexes/myxboxgames/docs/autocomplete?search&api-version=2020-06-30
{
"search": "minecraf",
"suggesterName": "sg"
}
B: In Azure Cognitive Search, typeahead or "search-as-you-type" is enabled through a
suggester. A suggester provides a list of fields that undergo additional tokenization,
generating prefix sequences to support matches on partial terms. For example, a suggester
that includes a City field with a value for "Seattle" will have prefix combinations of "sea",
"seat", "seatt", and "seattl" to support typeahead.
F. Use the default standard Lucene analyzer ("analyzer": null) or a language analyzer (for
example, "analyzer": "en.Microsoft") on the field.
Reference:
https://docs.microsoft.com/en-us/azure/search/index-add-suggesters
You are developing the smart e-commerce project.
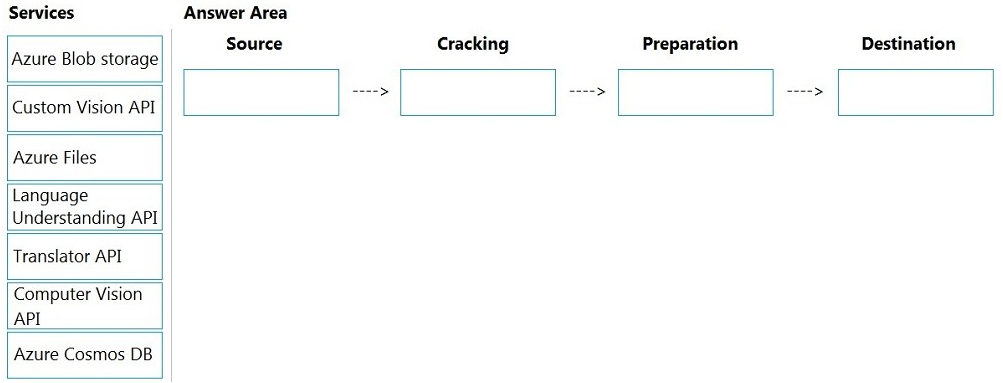
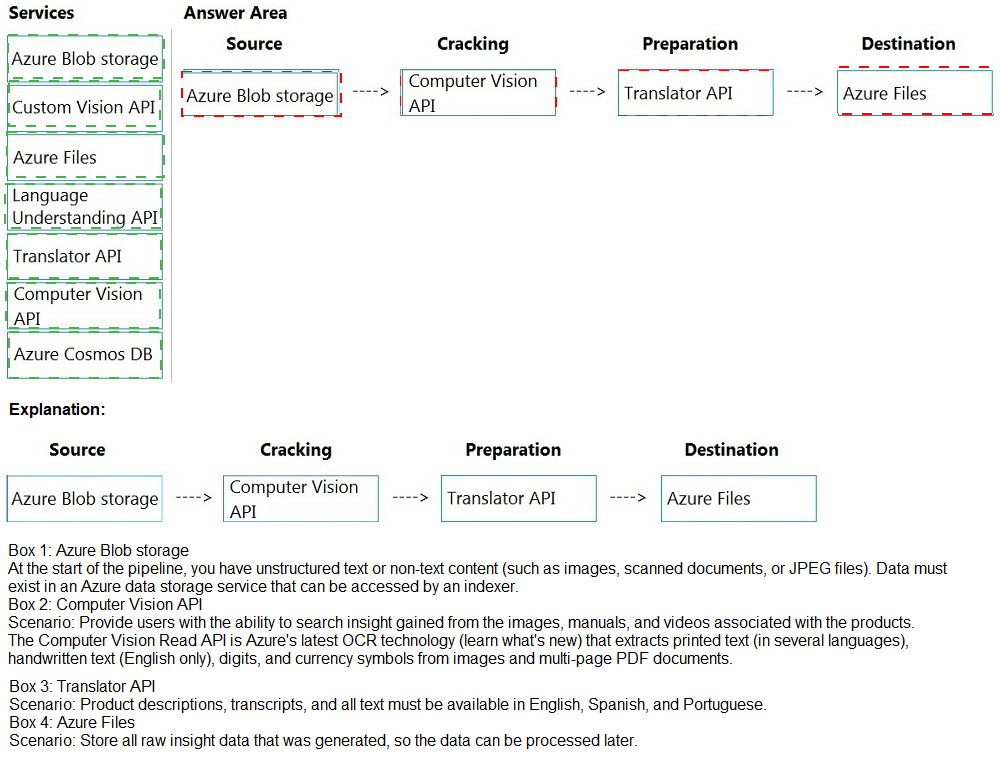
You need to design the skillset to include the contents of PDFs in searches.
How should you complete the skillset design diagram? To answer, drag the appropriate
services to the correct stages. Each service may be used once, more than once, or not at
all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
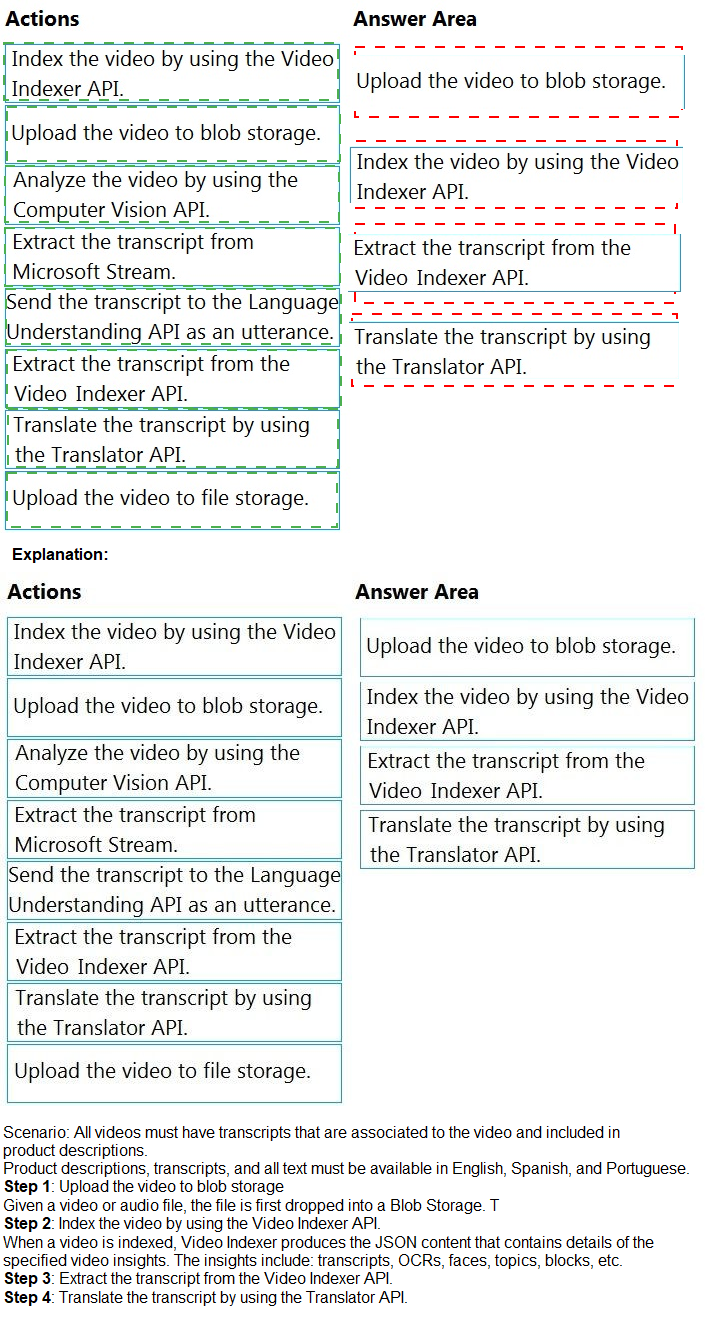
You are planning the product creation project.
You need to recommend a process for analyzing videos.
Which four actions should you perform in sequence? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
(Choose four.)

You need to develop an extract solution for the receipt images. The solution must meet the document processing requirements and the technical requirements.
You upload the receipt images to the From Recognizer API for analysis, and the API returns the following JSON.

Which expression should you use to trigger a manual review of the extracted information by
a member of the Consultant-Bookkeeper group?
A.
documentResults.docType == "prebuilt:receipt"
B.
documentResults.fields.".confidence < 0.7
C.
documentResults.fields.ReceiptType.confidence > 0.7
D.
documentResults.fields.MerchantName.confidence < 0.7
documentResults.fields.ReceiptType.confidence > 0.7
Explanation:
Need to specify the field name, and then use < 0.7 to handle trigger if confidence score is
less than 70%.
Reference:
https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/api-v2-
0/reference-sdk-api-v2-0
You are developing the document processing workflow.
You need to identify which API endpoints to use to extract text from the financial
documents. The solution must meet the document processing requirements.
Which two API endpoints should you identify? Each correct answer presents part of the
solution.
NOTE: Each correct selection is worth one point.
A.
/vision/v3.2/read/analyzeResults
B.
/formrecognizer/v2.0/prebuilt/receipt/analyze
C.
/vision/v3.2/read/analyze
D.
/vision/v3.2/describe
E.
/formercognizer/v2.0/custom/models{modelId}/ analyze
/formrecognizer/v2.0/prebuilt/receipt/analyze
/vision/v3.2/read/analyze
Explanation:
C: Analyze Receipt - Get Analyze Receipt Result.
Query the status and retrieve the result of an Analyze Receipt operation.
Request URL: https://{endpoint}/formrecognizer/v2.0-
preview/prebuilt/receipt/analyzeResults/{resultId}
E: POST {Endpoint}/vision/v3.2/read/analyze
Use this interface to get the result of a Read operation, employing the state-of-the-art
Optical Character Recognition (OCR) algorithms optimized for text-heavy documents.
Scenario: Contoso plans to develop a document processing workflow to extract information
automatically from PDFs and images of financial documents
The document processing solution must be able to process standardized financial documents that have the following characteristics:
- Contain fewer than 20 pages.
- Be formatted as PDF or JPEG files.
- Have a distinct standard for each office.
*The document processing solution must be able to extract tables and text from
the financial documents.
The document processing solution must be able to extract information from receipt
images.
Reference:
https://westus2.dev.cognitive.microsoft.com/docs/services/form-recognizer-api-v2-
preview/operations/GetAnalyzeReceiptResult
https://docs.microsoft.com/en-us/rest/api/computervision/3.1/read/read
You are developing the knowledgebase by using Azure Cognitive Search.
You need to build a skill that will be used by indexers.
How should you complete the code? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.

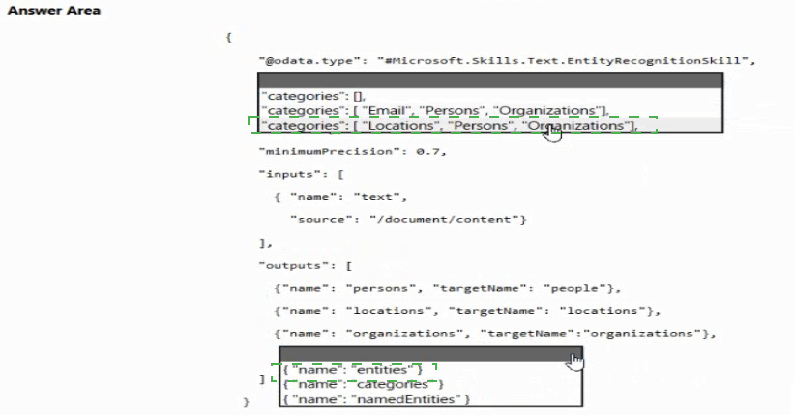
Explanation:
Box 1: "categories": ["Locations", "Persons", "Organizations"],
Locations, Persons, Organizations are in the outputs.
Scenario: Contoso plans to develop a searchable knowledgebase of all the intellectual
property
Note: The categories parameter is an array of categories that should be extracted. Possible
category types: "Person", "Location", "Organization", "Quantity", "Datetime", "URL",
"Email". If no category is provided, all types are returned.
Box 2: {"name": " entities"}
The include wikis, so should include entities in the outputs.
Note: entities is an array of complex types that contains rich information about the entities
extracted from text, with the following fields
name (the actual entity name. This represents a "normalized" form)
wikipediaId
wikipediaLanguage
wikipediaUrl (a link to Wikipedia page for the entity)
etc.
| Page 1 out of 26 Pages |
Copyright © - All Rights Reserved